6. Data Visualization
Story Engine dynamically creates data visualizations based on the data that are being interrogated. Users can choose from 3 presentation styles:
Connection Map -- communications between people.
Tree Map -- conceptual clustering.
Cards -- summary descriptions of unusual activity.
A. Connection Map
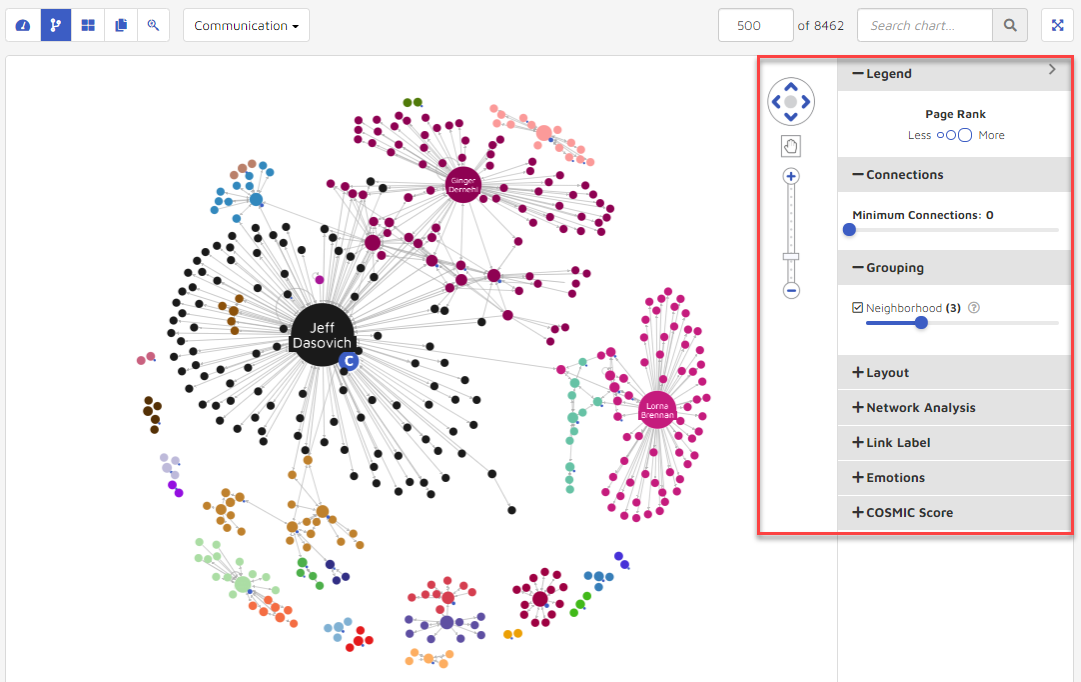
Connection Map is used to draw communication relationships between different people. The visualization shows a person’s name, with whom he/she communicates, and how many times they communicate. To the right of the map are tools for navigation and, by clicking on the arrow to the right, various tools for modulation. See highlighted area below:
Navigation control
The Navigation Control lets users move, zoom in/out or drag the visualization.
Click the
 icon to move the visualization up, down, left or right.
icon to move the visualization up, down, left or right.Click the
 or
or  icon to switch between sticky mode and click mode. In sticky mode, a user can drag around the entire visualization or any element. In click mode you can draw a box around multiple elements and then drag them as a group.
icon to switch between sticky mode and click mode. In sticky mode, a user can drag around the entire visualization or any element. In click mode you can draw a box around multiple elements and then drag them as a group.Click the
 and
and  icon on the zoom bar to zoom in and zoom out of the visualization.
icon on the zoom bar to zoom in and zoom out of the visualization.Clicking the arrow on the right side of the screen will expand a Settings panel to modify how users can visualize their data. Options include a legend, connections, grouping, layout, network analysis, link label, emotions and COSMIC score.
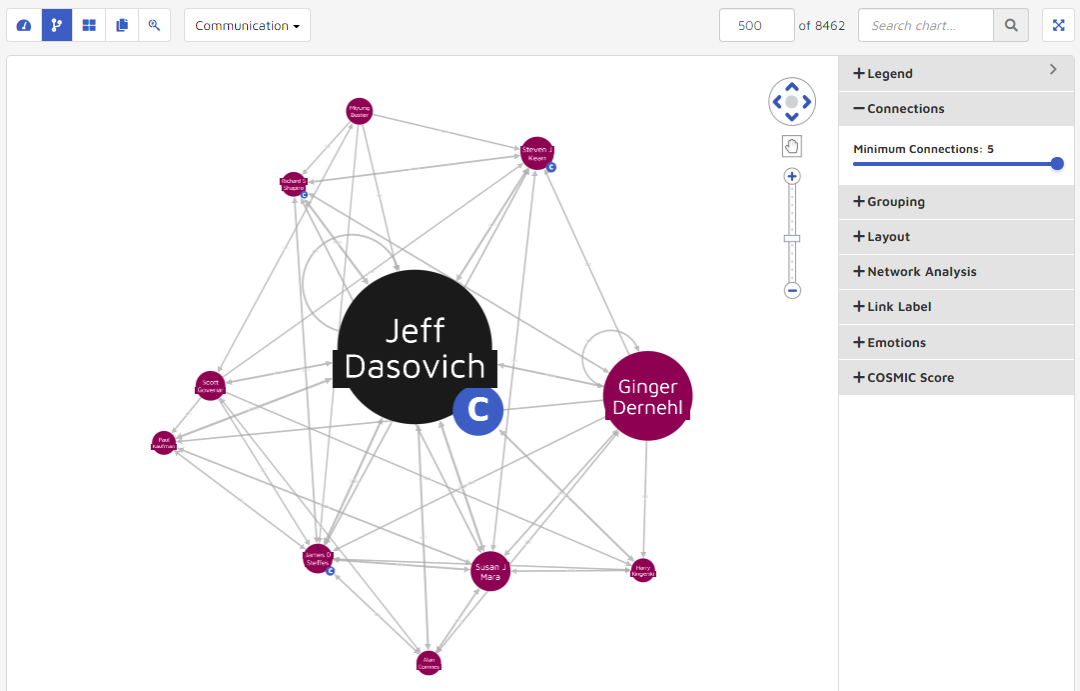
Connections
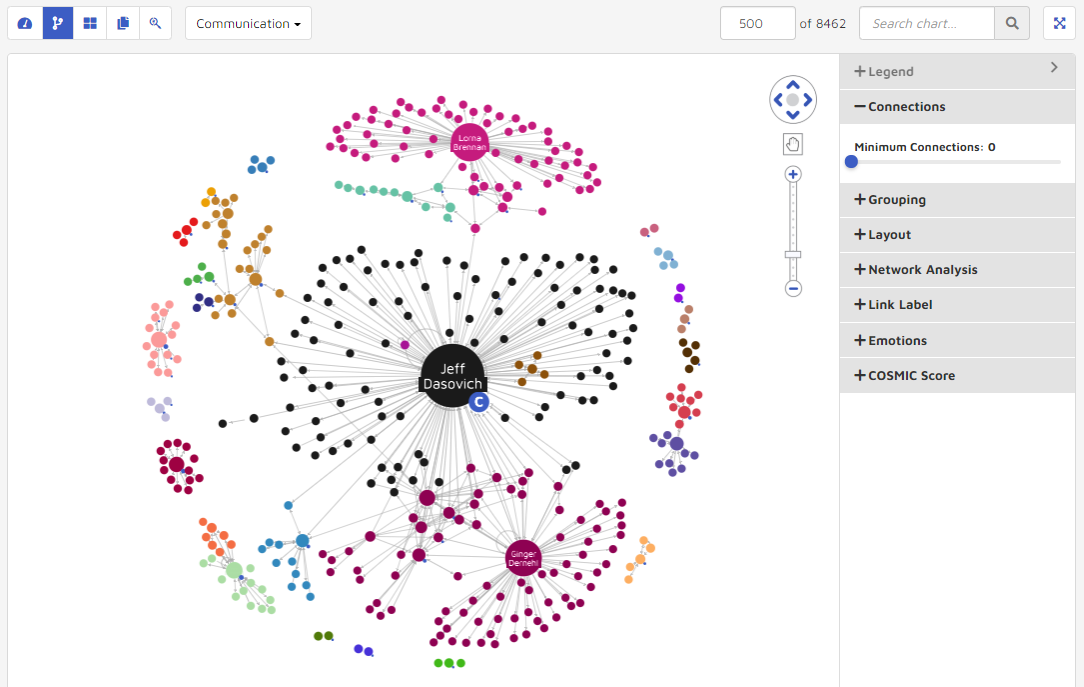
One way to adjust visualization and reduce clutter is by using minimum connections. The connections function calculates a graph where each node has a desired number of connections. A user can use the Minimum Connections slide bar to specify the connections values desired.
For example, the following graphic shows the visualization before and after changing the connections value from 1 to 6.
Grouping
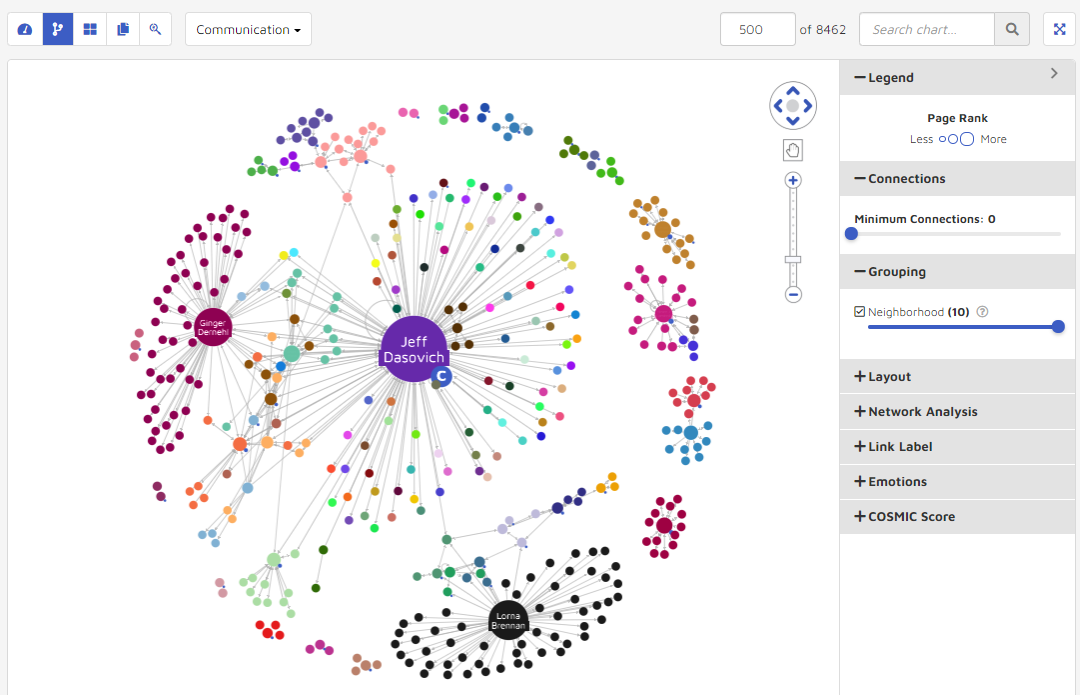
The grouping feature affects how nodes cluster within the data visualization. Higher values give smaller clusters, but more of them. Lower values give larger clusters, but not as many. The range is from 0 to 10. The following graphics show a change from having the setting turned off, to changing “Neighborhoods” to 10. The data visualization uses more colors when the neighborhood setting is higher.
Neighborhoods turned off.
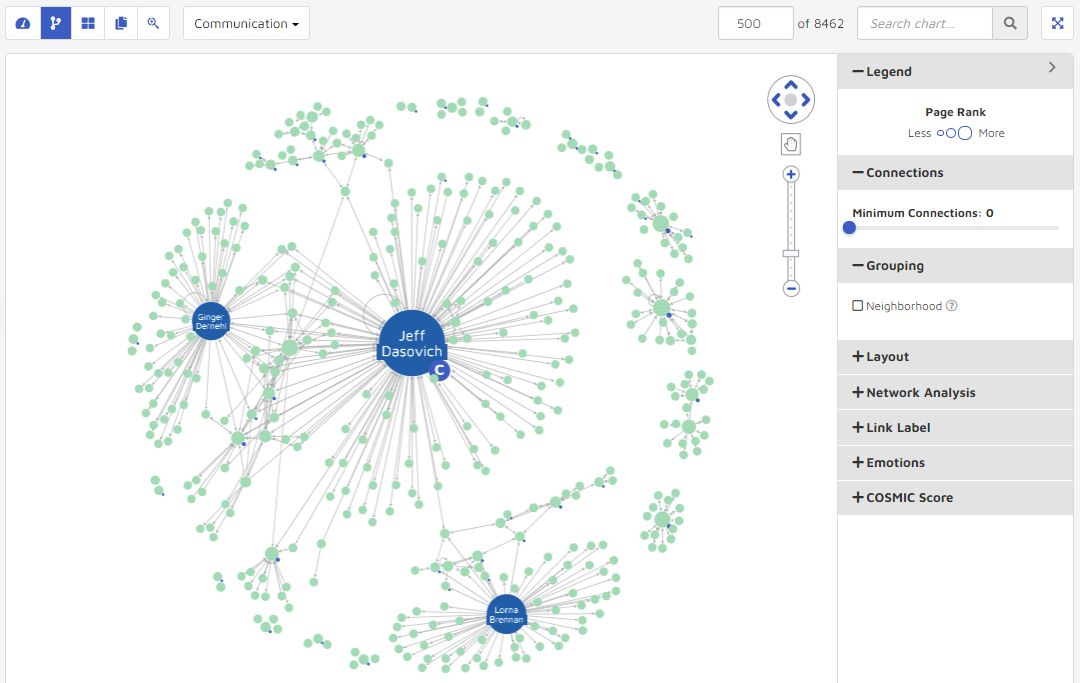
Neighborhoods set to 10.
Layout
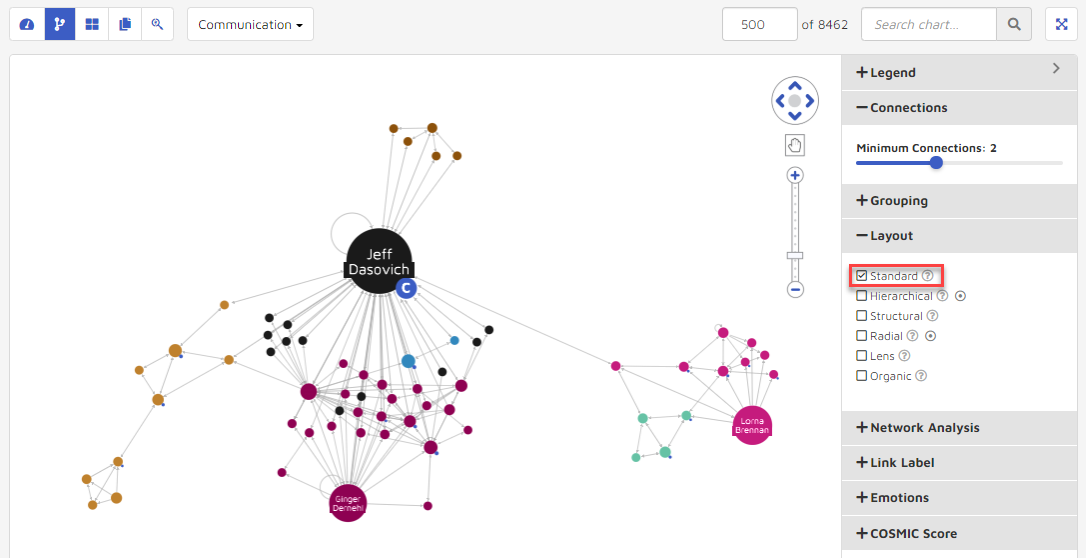
Layout determines the orientation of data visualized. By combining different combinations of Layout, Network Analysis, Grouping, etc., users can fully visualize and interrogate their data. Visualization arrangements support the following:
Standard: an efficient force-directed graph layout. Nodes and edges overlap as little as possible and are evenly spaced out.
Hierarchical: lays out nodes in a top down arrangement according to their connections. Like a family tree, children are shown below their parents in a top-down display.
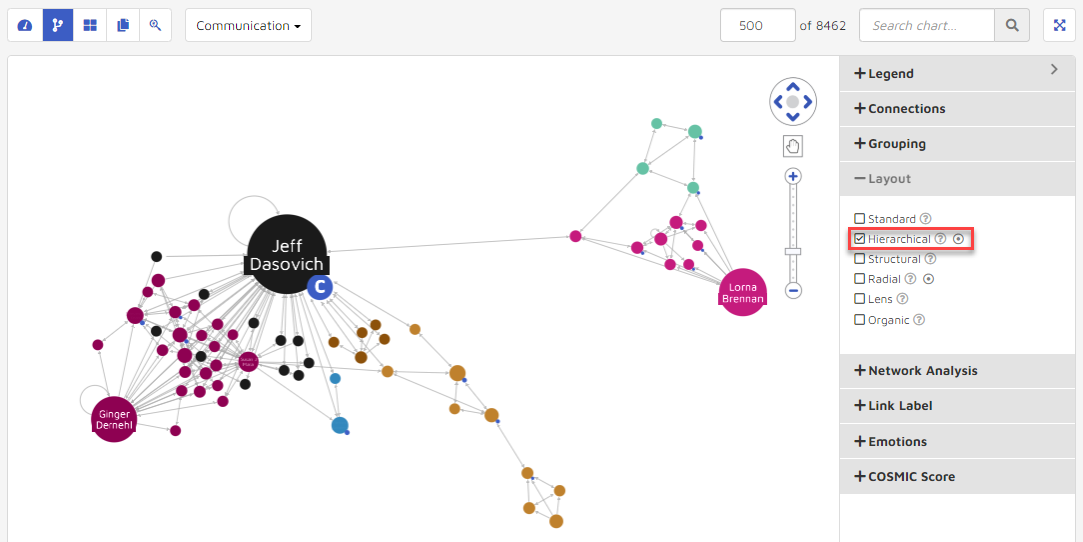
Structural: places nodes which are structurally similar together in the network. Similar nodes are grouped together in fans.
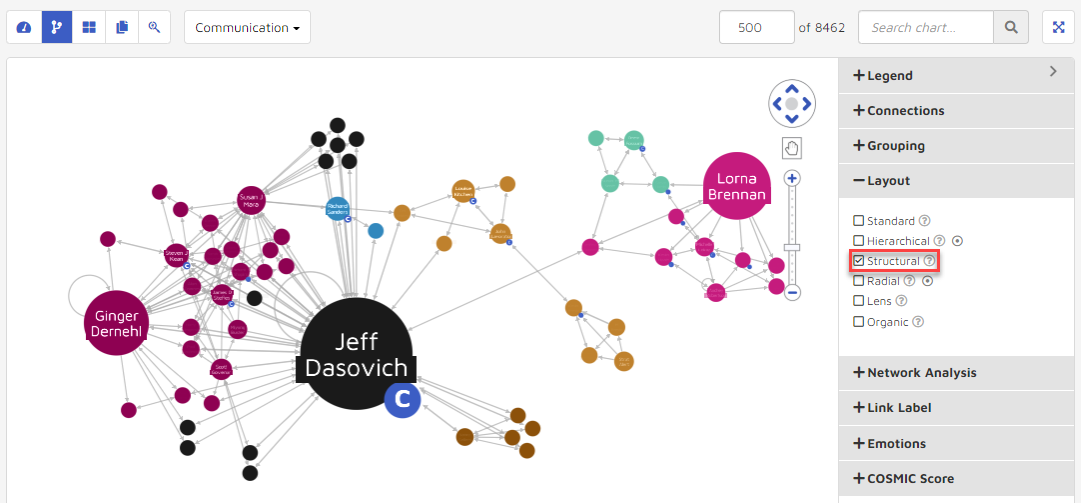
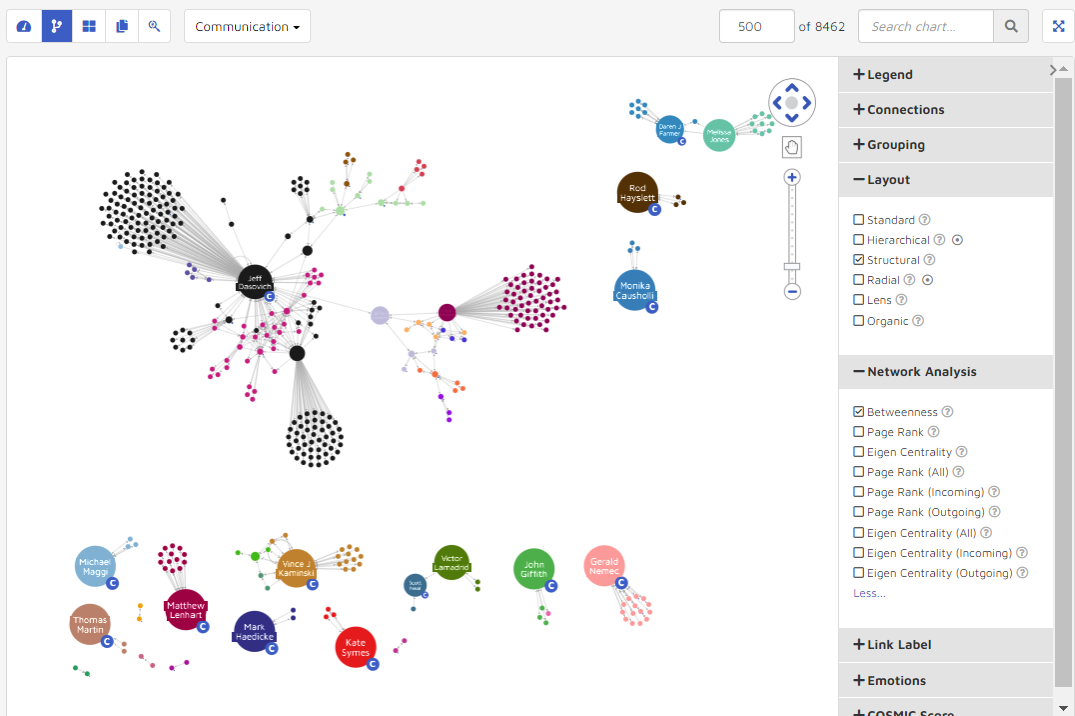
Radial: Nodes are arranged in circles around the original subject.
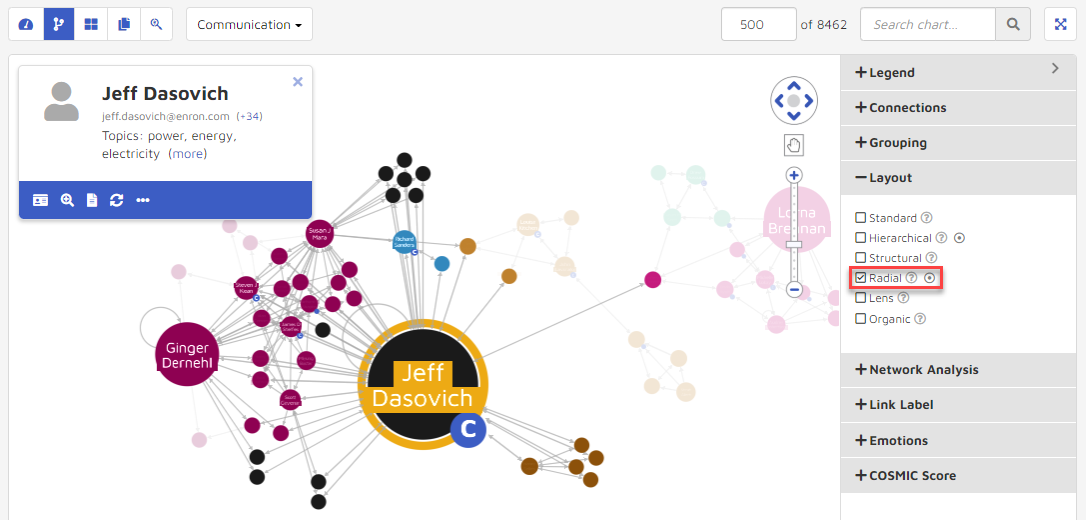
Lens: Highly connected nodes are pushed to center while less connected nodes are along the edge.
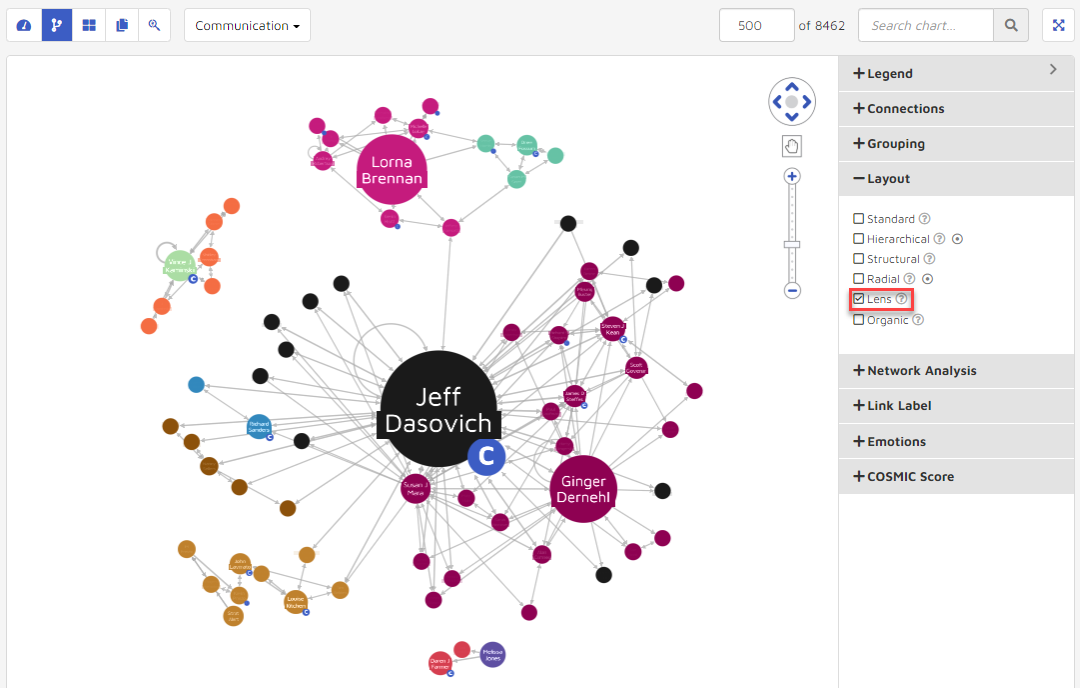
Organic: Untangles big networks and give a distinctive fan-like pattern to related groups of nodes.
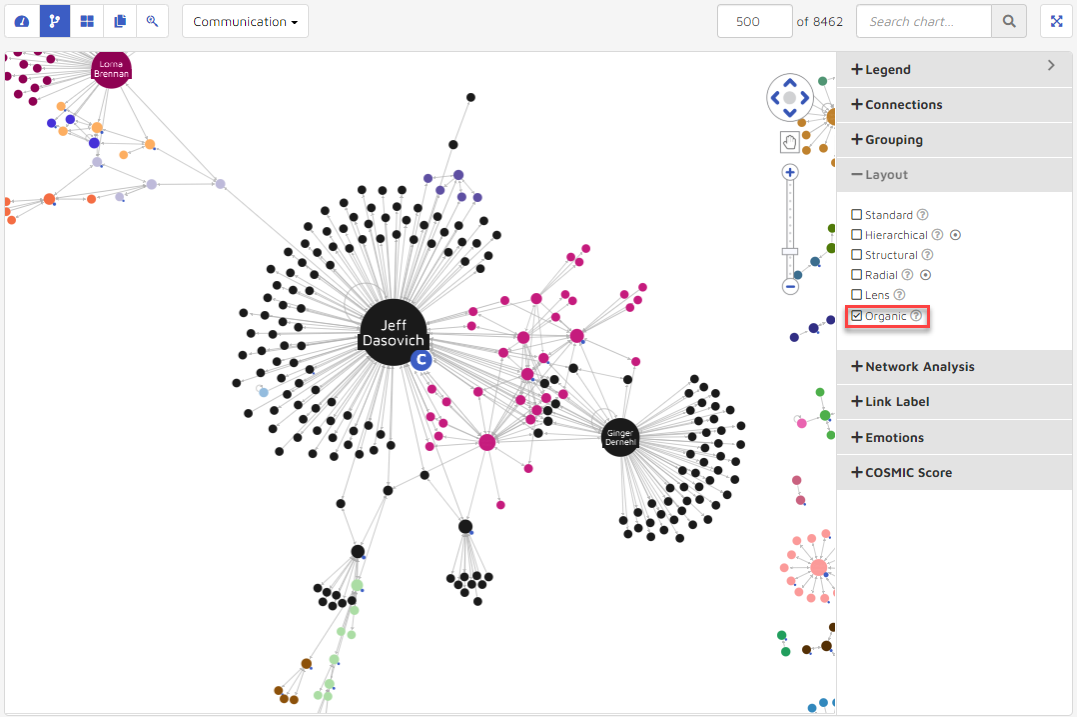
Network Analysis
The Network Analysis settings are used to change how nodes within the data visualization are highlighted and oriented. Options include Betweenness, Page Rank (All, Incoming, Outgoing) and Eigen Centrality (All, Incoming, Outgoing). By hovering over the tool tip “question mark” icon users can see what will determine how the nodes are highlighted.
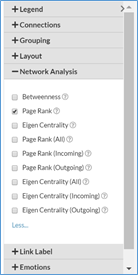
Betweenness: Highlights nodes with more connections between 2 or more other nodes.
Page Rank: Highlights nodes based on number of incoming links.
Eigen Centrality: Highlights nodes with influence by the number of links each person has and the number of links their connections have.
Page Rank (All): Highlights nodes based on number of links with communication count.
Page Rank (Incoming): Highlights nodes based on number of links with received emails.
Page Rank (Outgoing): Highlights nodes based on number of links with sent emails.
Eigen Centrality (All): Highlights nodes with influence by the number of links each person has received/sent and the number of links their connections have.
Eigen Centrality (Incoming): Highlights nodes with influence by the number of links each person has received and the number of links their connections have.
Eigen Centrality (Outgoing): Highlights nodes with influence by the number of links each person has sent and the number of links their connections have.
For example, the following graphic shows the data visualization before and after changing the Network Analysis value to Betweenness in Structural Layout compared to Page Rank Outgoing in Lens Layout.
Link Label
Link Label is used to annotate the inflow and outflow of messages to provide context for the communication patterns of 2 people.

In Communication mode, a user can further show Segment Volumes (how many total emails entity A sent and received from entity B), or Reciprocity and Volume (number of emails entity A sent vs. number of emails entity A received).
Segment Volume
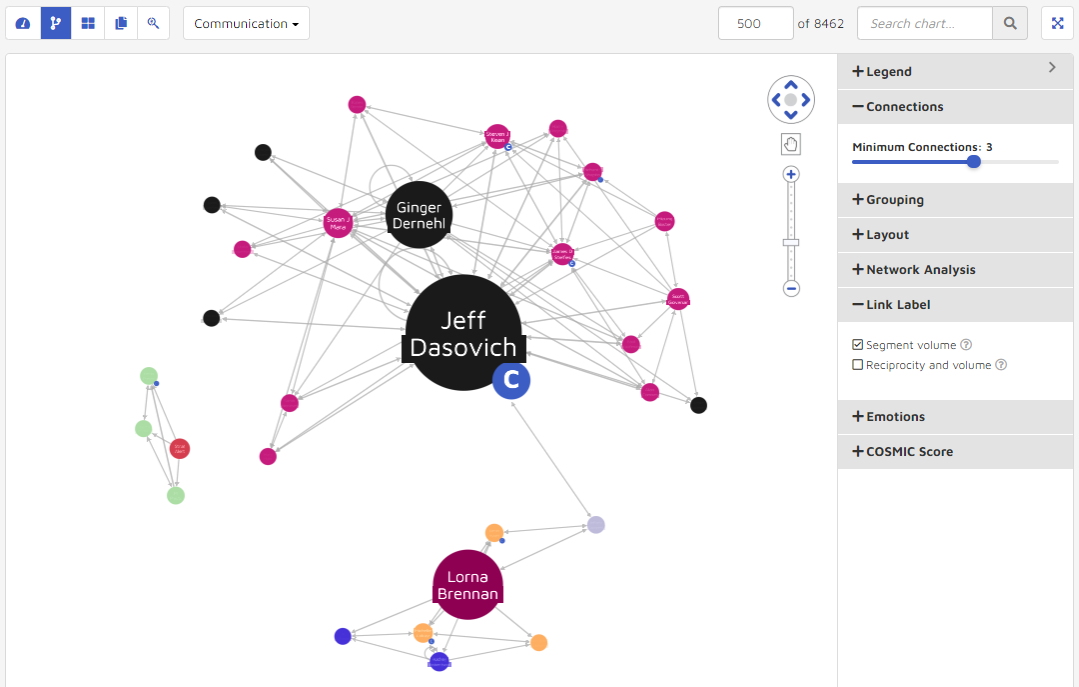
Reciprocity & Volume
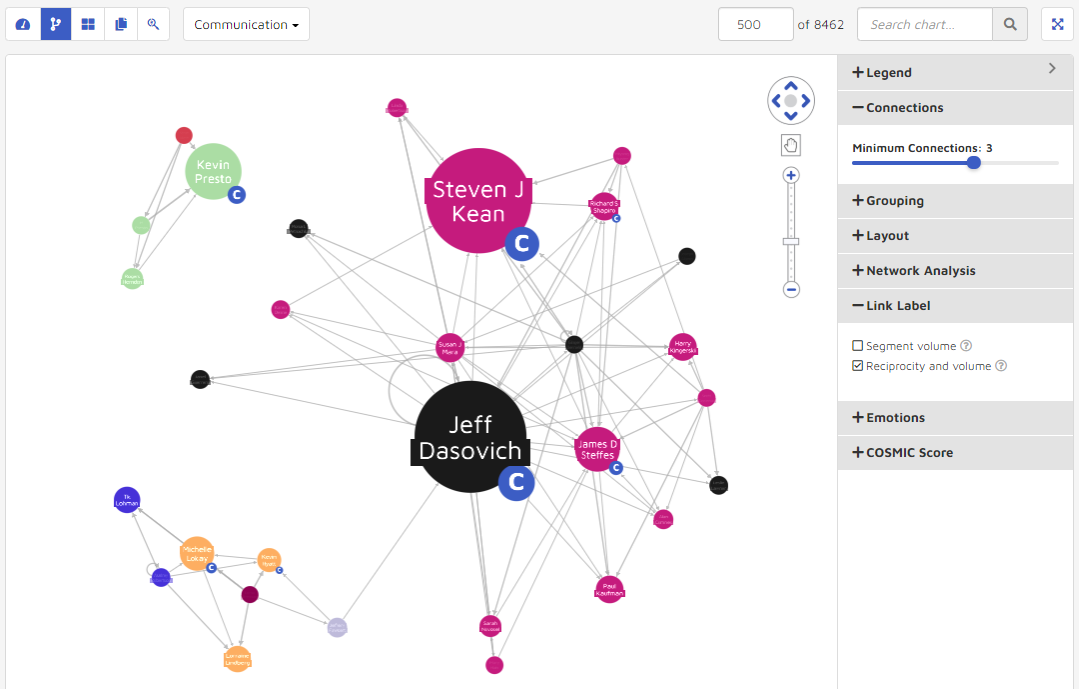
Under the Reciprocity and Volume mode, the numbers on the links represent the ratio and the total emails. For example, the link between Jeff Dasovich and Ginger Dernehl is “1.1(576)”, which means there are 576 emails overall between Jeff and Ginger. For each 1.1 emails Jeff sent to Ginger, Ginger responded once.
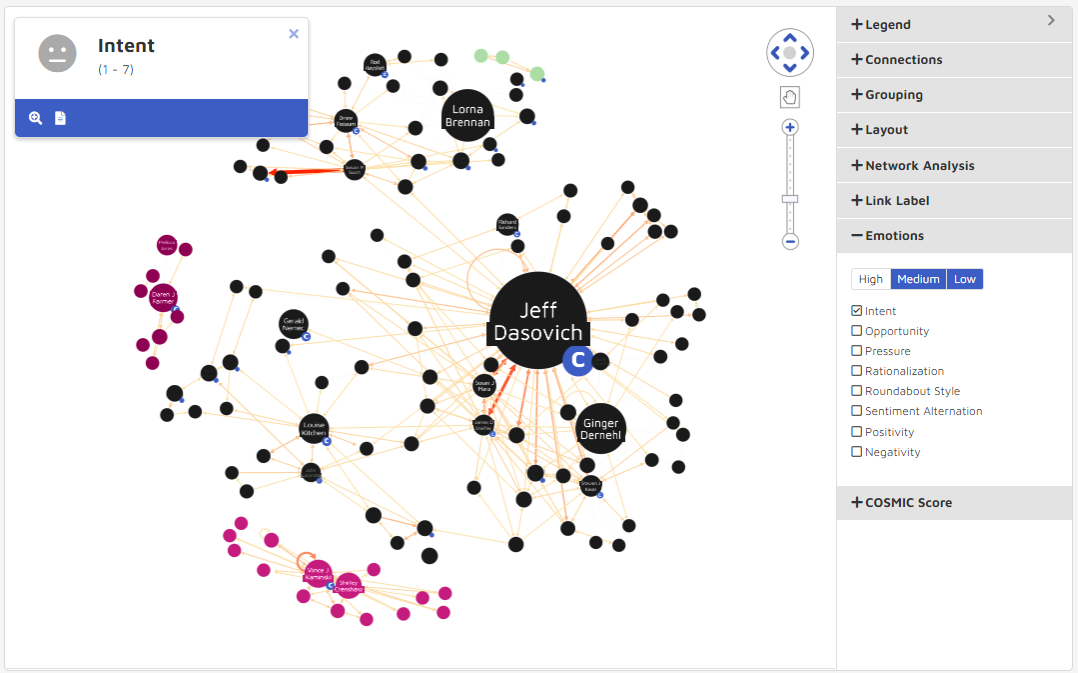
Emotions
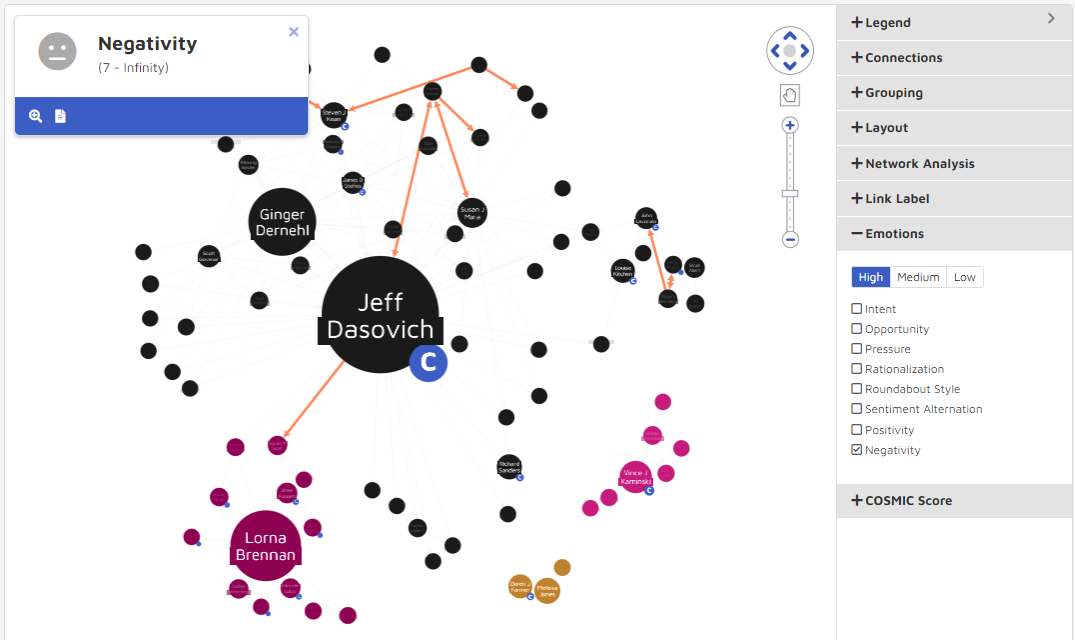
In the settings panel users can overlay any emotional intelligence models to visualize communication patterns and find documents expressing specific sentiments. Using High, Medium and Low cutoff thresholds users can choose from Intent, Opportunity, Pressure, Rationalization, Positivity and Negativity score filter conditions to be used separately.
The following graphic details the changes in visualization from a High Negativity setting to a Medium-Low Intent Score. Note that users can set a range for the High to Low, but may only choose one score setting at a time. The thickness of the line between connections is representative of the how strong the communication fit the emotions, so below, you can see the difference in communication patterns when switching between High Negativity and Low-Medium Intent scores.
COSMIC Score
The COSMIC feature only works after COSMIC has been run at least once. A user selects from predefined High, Medium, or Low values for any COSMIC models that are a part of their storybook.
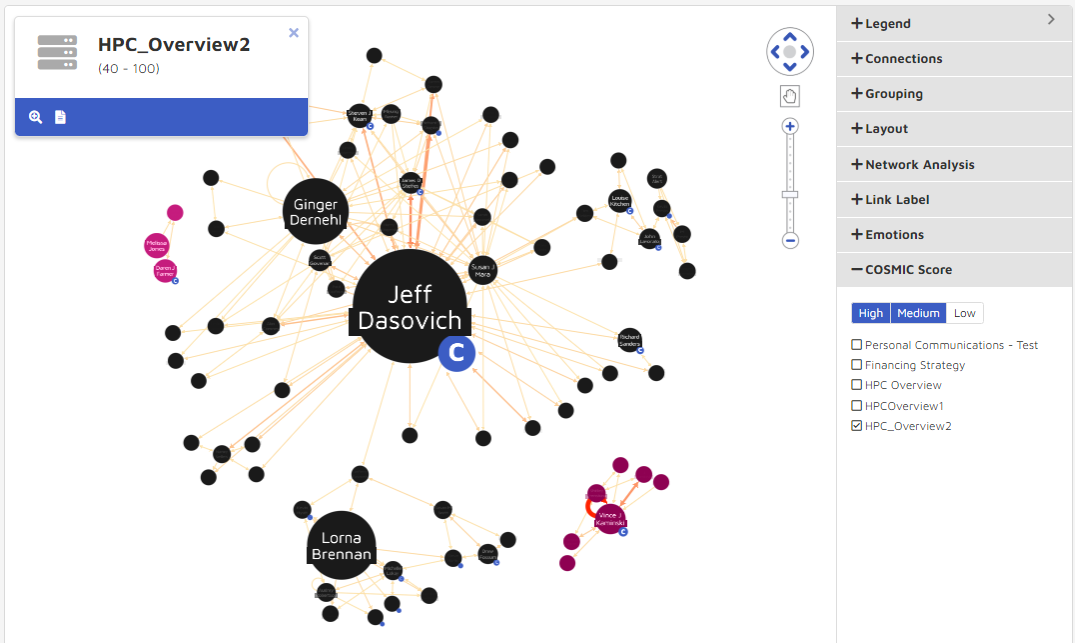
The graphic below shows the changes in visualization from a “Hot” COSMIC model with only High and Medium documents compared to an “Important” COSMIC model returning only low documents. Note that you can choose a range of thresholds, but only one model. The thickness of the line between connections represents how well the documents between the nodes fit the chosen COSMIC model.

Time Chart
The Time chart displays the visualization with time information. The time bar is located at the bottom of the visualization when a user selects this mode.
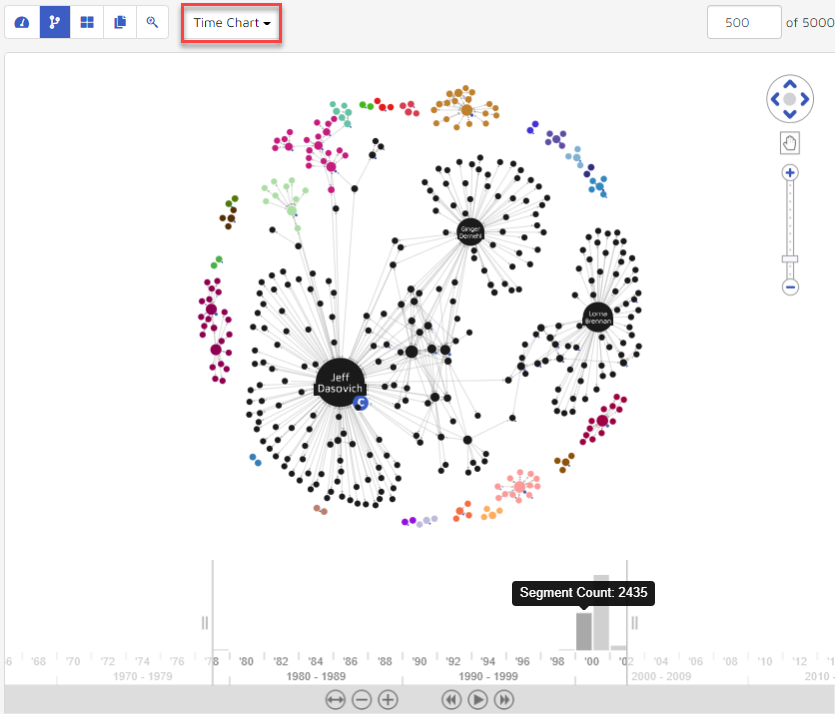
The time bar at the bottom represents the frequency of communications for each time period. A user can use their mouse scroll wheel to zoom in and zoom out the time period. The visualization will update and reflect who has communications within the selected time range (between the two vertical lines on the time bar).
Double-click the link between the persons. Associated documents will open in the date range selected. For example, the graphic below shows the same data as above when zooming in to focus on Aug 22nd, 2001.
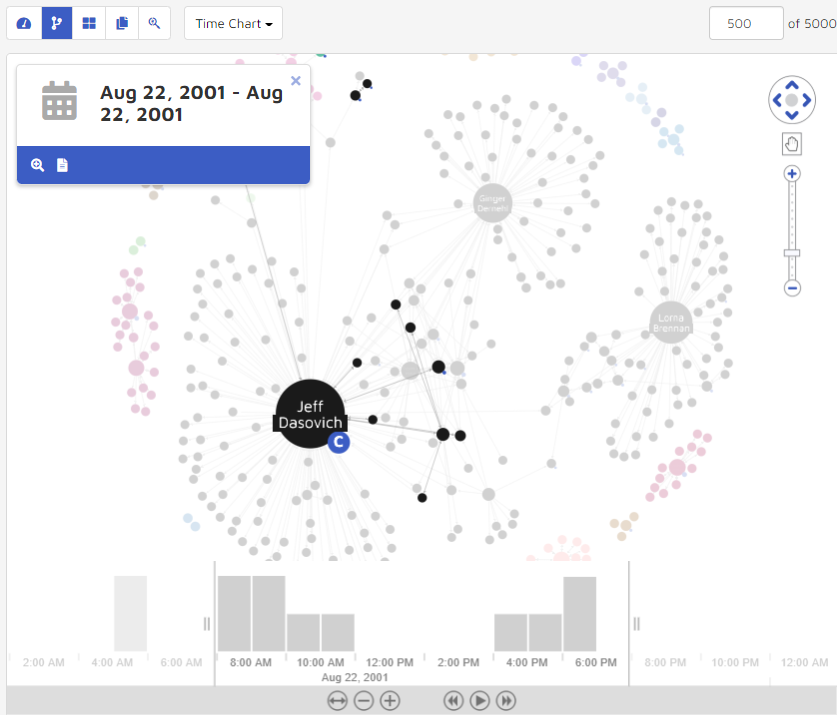
By clicking the Add to search button, users can return all threads that fall within time period. Users can then interrogate data from a specific time period more thoroughly. Clicking the View Documents button allows users to parse through the threads and documents in the thread viewer.
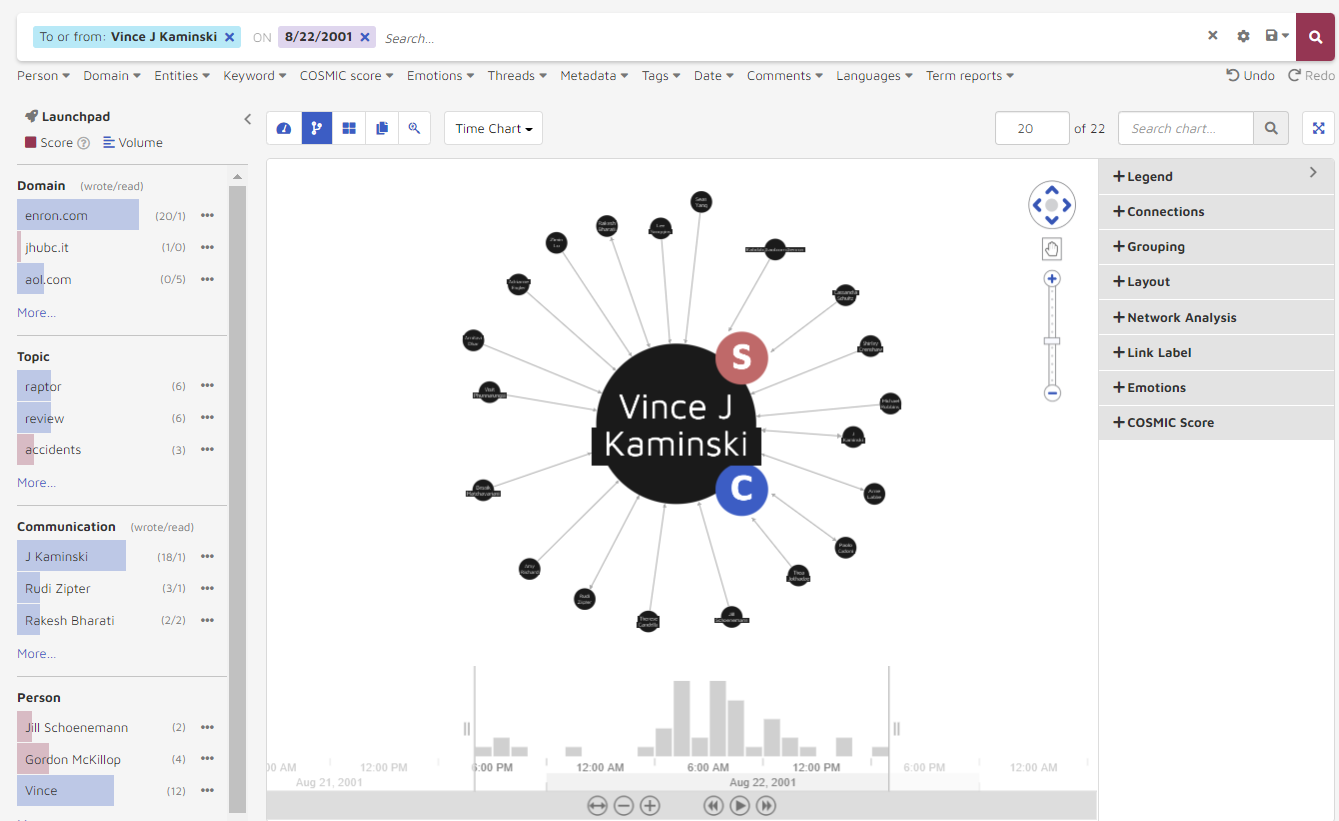
Maximum Connections and Search Chart Function
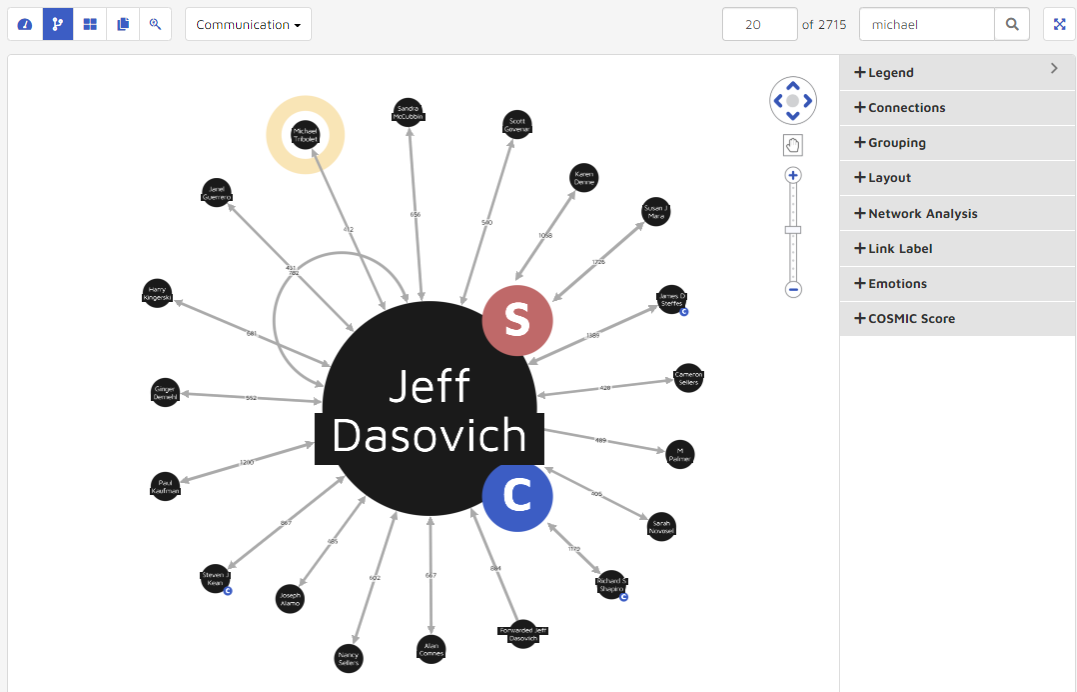
String search lets a user find entities in the visualization quickly when too many entities are loaded. For example, the following graphic shows “Michael Maggi” and “Michael Tribolet” when a user enters “Michael” then clicks the Search button:
· Max Links: Lets a user specify how many pairs of relationships to load into the visualization. By default, the application loads the top 500 relationships. A user can increase or decrease the number by entering the desired number and then hitting Enter on their keyboard.
The application also gives you the total pairs of relationships the current data set represents.
Glyphs
There are 2 glyphs used to represent the identity of the entities in the visualization:
S (selection): Indicates that person is part of the search criteria.
C (custodian): Indicates that person is a custodian.
Selection Indicator
 .
.Custodian Indicator
 .
.
B. Tree Map
The tree map is a visual representation of NexLP’s intelligent clustering technology. There are two important visual factors: size and color. A bigger size of block represents larger amount of documents, while darker color represents more hits are from the underlying cluster when you run a search. Running a search for a person, topic, etc. will show which clusters have the most segments related to the search as darker boxes have more relevant hits.
At any point, users can click on the “data” icon to view the contents of the cluster, or users can continue honing in on the clusters until they can go no further.
Navigation Control
Tree mapping in Story Engine visualizes documents by clustered segments. Documents in each segment are clustered based on the subject matter topics discussed with highly involved documents being a darker shade and segments with more documents being larger. Users can also choose to expand the data visualization to full screen by clicking the Expand button in the upper right corner.
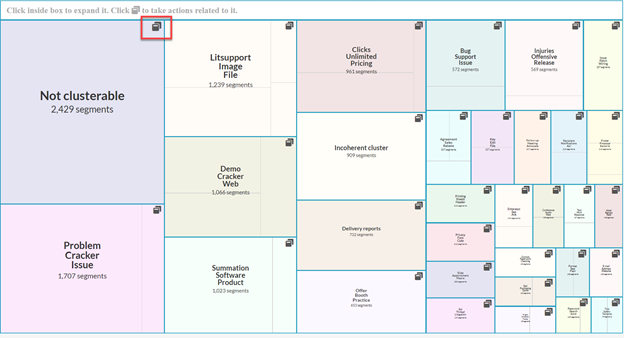
Clicking the “preview” button in the upper right corner of each box shows the topics discussed in the segment while clicking inside the box expands it. From the quick description box you can Add to search or View documents by clicking the buttons in the bottom left corner of the pop-up box. In the thread previewer on the right side of the screen, users can look at document threads that the segment would return by searching the segment.
Tree map with searching
As detailed earlier in Section 3 and Section 5, users can add keywords and filter conditions to modulate the data visualization as they desire in Cluster Tree Mapping just like in Connection mode. The graphic below demonstrates how adding filters to the search from the Entity Launchpad and Search bar changes the data visualization in the central panel.
From the COSMIC models setting, choosing ”Hot” documents with a high probability returns 1,754 threads.
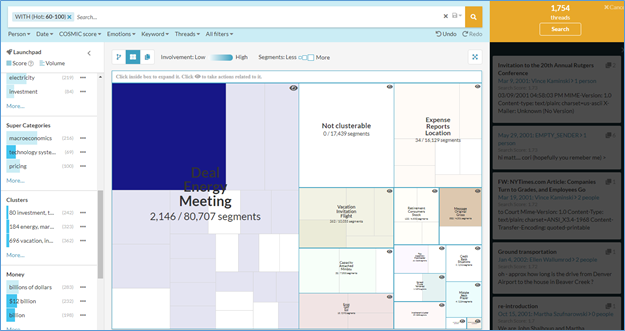
Adding the super category “Technology systems” to the search by selecting it from the Launchpad's Super Categories list further narrows the returned threads to 67, allowing the user to search through only documents that are deemed to have a high probability of being “Hot” in the super category of “Technology Systems”.
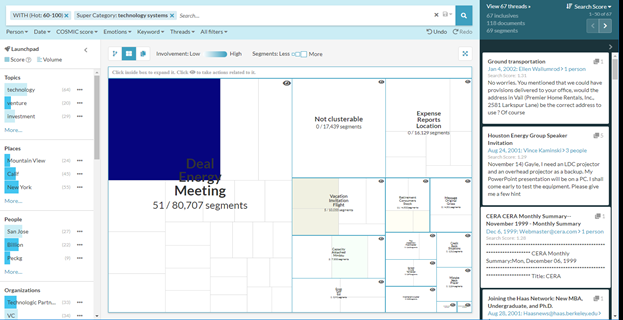
Clicking in the boxes will lead you to the most densely populated cluster of Investment Technology Service which holds 45 segments of the overall 67 threads.
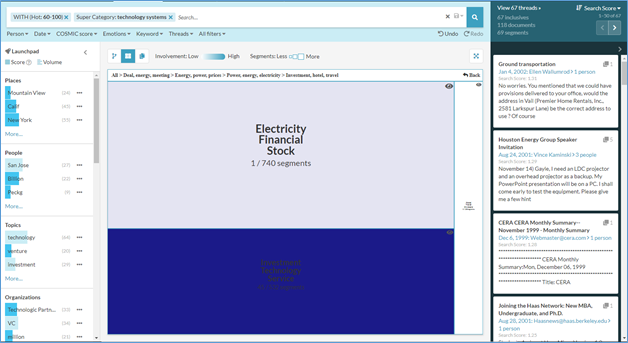
After clicking the View Documents button, users can parse through the returned documents in the thread viewer, to analyze the text of the document itself.
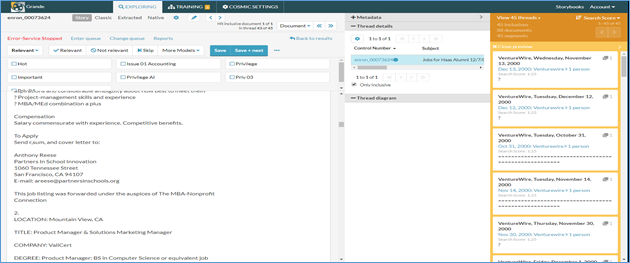
C. Cards
Cards represent patterns in a user’s data. Starting from Version 2.0, Story Engine provides a new visualization for presenting patterns. Combined with searching conditions, Cards provides a powerful way to pinpoint patterns involving a person, a topic, or a specific period, that Reveal AI detects in the dataset.
The Cards view is available by clicking on the “Cards” ( ) button. “Cards” mode dynamically builds around a set of documents, and presents stories found from the dataset. The side bar color represents uniqueness scores. Darker color means more unique, or higher abnormal score.
) button. “Cards” mode dynamically builds around a set of documents, and presents stories found from the dataset. The side bar color represents uniqueness scores. Darker color means more unique, or higher abnormal score.
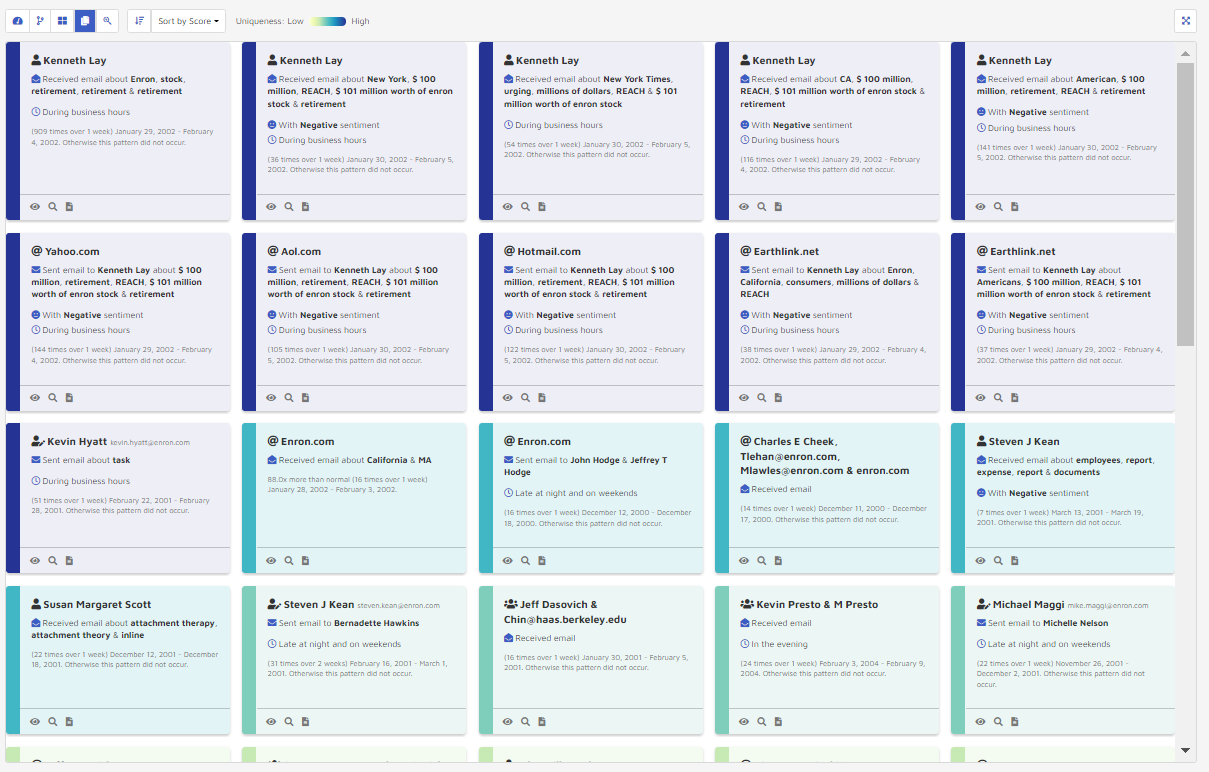
Based on the summary, users can quickly identify who was involved, what they were talking about, when and how they were talking about it, and at what time.
By clicking on the Sort by button, Cards can be ordered in ascending or descending orientation, sorted by score, count, weeks, sentiment, or work shift.
Score: Ordered by pattern score.
Count: Ordered by how many times the pattern was detected overall.
Weeks: number of weeks the pattern exists.
Sentiment: Ordered by how strong the negative or positive sentiment is.
Work shifts: Ordered depending on when the pattern was detected (Work hours, evening work hours, or nights and weekends).
Based on the color of the vertical bar on the left side of each card, users can determine whether the pattern displayed on the card is unique or common. For example, the samples below shows patterns from very unique score (blue), to moderately unique score (green) and common unique score (yellow).
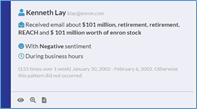
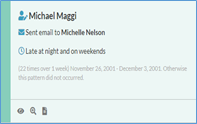
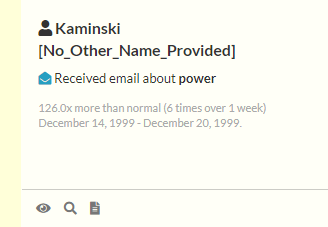
While in “Card” visualization mode, Story Engine loads data anomalies identified from the dataset onto the Pattern Card. In the bottom left corner of each card, users can Preview, Add to search or View documents. Clicking Preview will load the document snippets on the right side of the screen, allowing users to view a snippet of documents belonging to that pattern.
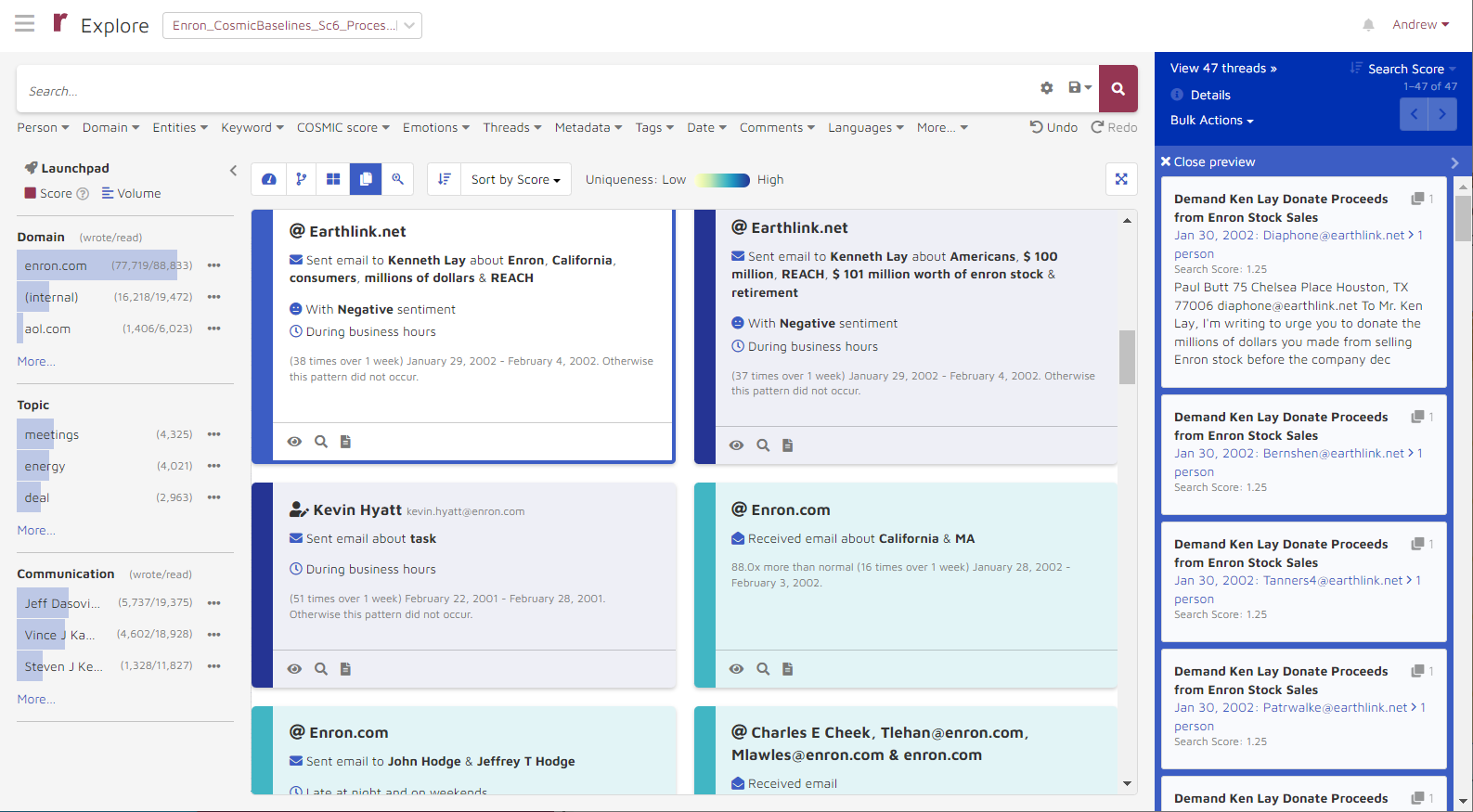
Clicking on View documents will populate the thread viewer with the documents from the pattern.
Users can search patterns by using the global search bar. For example, if users want to identify all patterns associated with Vince Kaminski, they can search “Vince” in Person, click Search, and it loads all patterns associated with Vince.
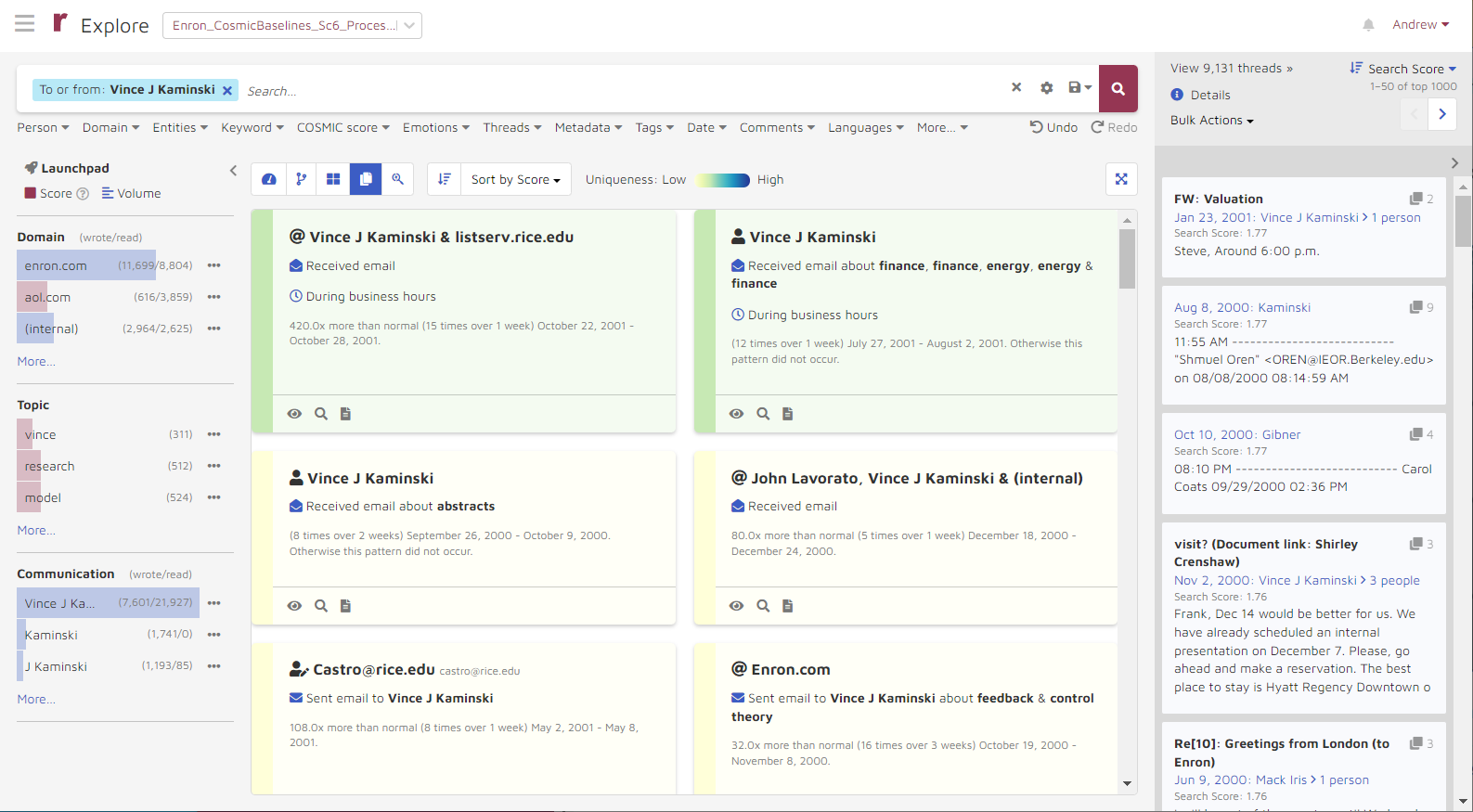
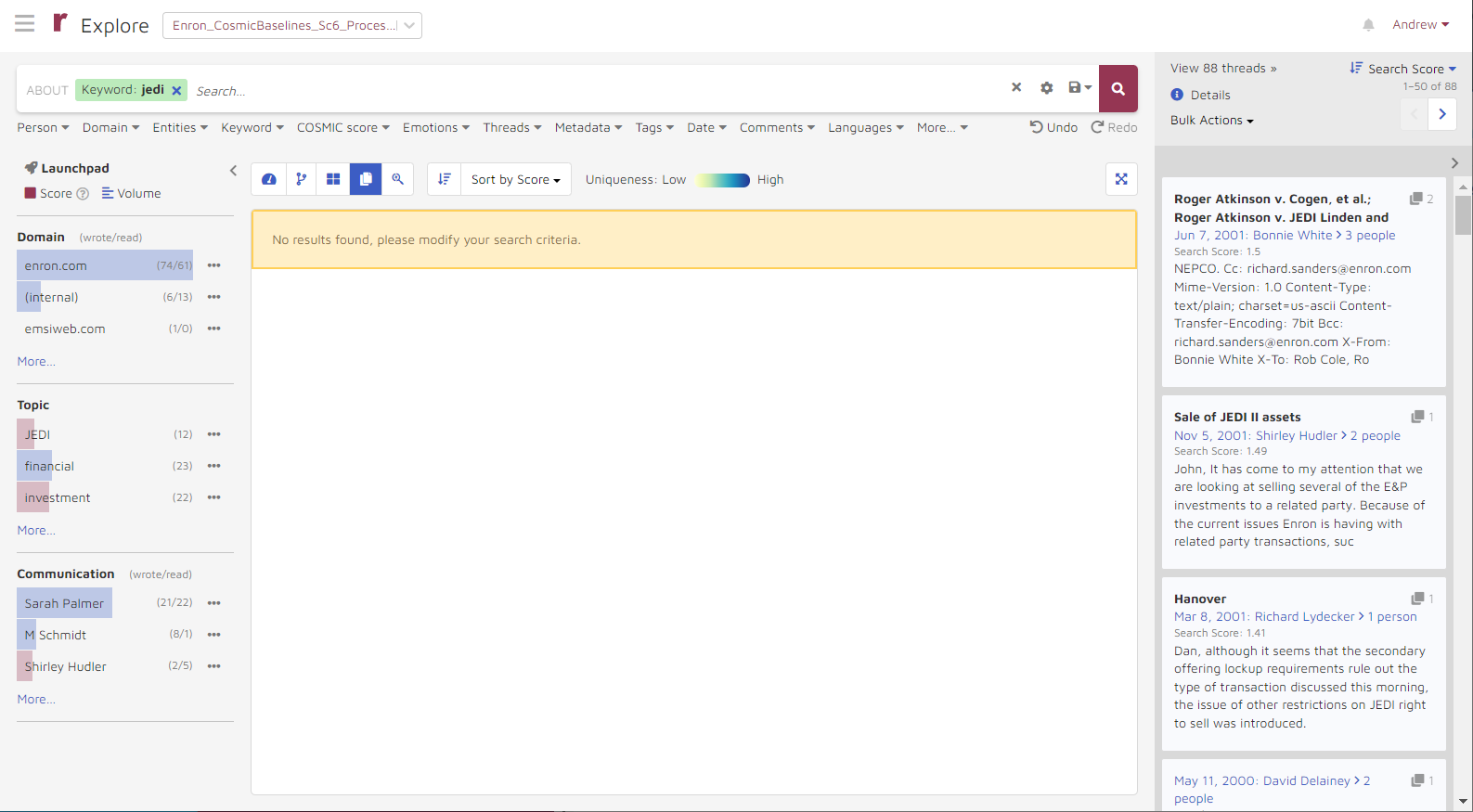
In some cases, adding a certain combination of search conditions will return no patterns or cards. In this scenario, the panel will read No results found, please modify your search criteria. However, any documents related to your search will still appear in the document previewer on the right side of the screen.