Reveal Cloud AI Installation
1 General Description and Setup
1.1 Overall Description
The Cloud AI platform of Reveal is essentially a middleware layer that handles communication with AWS for cloud analytic functions. At time of writing we support integration with AWS analytics only.
The system is comprised of multiple parts that may or may not be available depending on the makeup of the Reveal architecture accessing the system. The system is generally comprised of the following parts:
Orchestration This is a centralized server that maintains the following:
Mongo database
API on top of the mongo database
Several services that perform minimal work, e.g. Watching for AWS jobs to finish.
Archive Worker This is a server that is turned on when archiving work is available to be performed. Use of this functionality requires all data for your Reveal site to be stored in S3.
Transcription Worker This is a server that exists to perform heavy-lifting transcoding work on au-dio/video files.
As described above, while in this document we will describe these three as separate components, there's no reason they need to be separate. They in fact could all reside on the same server depending on the desired setup and server load.
All servers in this system are intended to run on CentOS-based Linux operating systems. There's no particular reason they cannot run on Windows as the code running the platform is python-based, however the documentation herein assumes CentOS Linux 8.4.2105.
Additionally if archiving is to be put in place within the system, there is an extra service that performs database backups necessary to be installed on the Review database server. Ignore all archiving-related instruction in this document if archiving is not being set up.
1.2 Setup Checklist
AWS Account Provisioned
Linux Servers Provisioned (CentOS 8.4.2105)
IAM Setup Items Done
KMS Key Setup Done
Network Security Allowed
Orchestration Server Setup Performed
Transcription Server Setup Performed
Review Reconfiguration Performed
1.3 Storage
Shorter description:
Orchestration 50GB root and 1TB storage.
Archive Worker 50GB root.
Transcription Worker 50GB root and 1TB storage.
Longer description:
Orchestration This server should have as much free space as the largest image labeling job you intend to run times 2. The reason being that part of the work the Orchestration server performs is syncing down images for image labeling jobs, then it may convert those files to AWS-usable formats. Thus taking up twice the space (potentially) for every image you submit for labelling at a single time.
Archive Worker This server needs very little storage space. Around a 50GB root should be plenty. The only thing that takes up space on the archive worker is archiving logs which are cleaned after every job.
Transcription Worker This server should have as much free space as the largest transcription job you intend to run times 2. Similar to image labeling, transcription jobs may require media transcoding which ends up creating an extra file for every audio/video file you send.
1.4 Resources
Orchestration In our production environment this is an AWS t2.medium (2CPU, 4GB RAM).
Archive Worker In our production environment this is an AWS t2.2xlarge (8CPU, 32GB RAM).
Transcription Worker In our production environment this is an AWS t2.2xlarge (8CPU, 32GB RAM).
1.5 Staging S3 bucket
The Cloud AI system uses an S3 bucket for staging purposes. This is necessary as AWS services require data to be stored locally in S3 for analysis to be performed. In this document we use the bucket name 'revealdata-analytics-temp-us'. Replace this in all policies with the name of your staging bucket.
The Cloud AI services to not automatically clean this S3 staging bucket. We suggest setting up a cleanup policy on this bucket to ensure that old data are properly deleted.
If you want to maintain data in a particular region, be careful to set up this staging bucket in the specific AWS region the data reside in.
1.6 Networking
By Source (outbound):
Source | Destination | Port | Reason |
|---|---|---|---|
Archive Worker | Orchestration Orchestration SQL Server SQL Server AWS | 27017 5000 1433 8500 443 | Queue Monitor and Queries API Queries Query databases Database Backup API Queries Allow communication to AWS resources |
Reveal Web Server | Orchestration | 443 | API Queries to add work. |
Orchestration | AWS | 443 | Allow communication to AWS resources |
SQL Server | AWS | 443 | Database backup upload (archiving only) |
Transcription Worker | AWS Orchestration | 443 27017 | Allow communication to AWS resources Queue Monitor and Queries |
By Destination (inbound):
Destination | Source | Port | Reason |
|---|---|---|---|
Orchestration | Worker Archive Worker Reveal Web Server Transcription Worker | 27017 5000 5000 27017 | Queue Monitor and Queries API Queries API Queries to add work. Queue queries. |
SQL Server | Archive Worker Archive Worker | 1433 8500 | Query databases Database Backup API Queries |
AWS | Archive Worker Transcription Worker SQL Server Monitor | 443 443 443 443 | Allow communication to AWS resources Allow communication to AWS resources Database Backup upload (archiving only) Allow communication to AWS resources |
Review also has the following networking requirements to link into this system:
Review Index Batch will need to query the Orchestration server via TCP 5000 and communicate with S3.
The Review Storage Service will need to be able to communicate with S3 in order to access finished data from the staging bucket.
TCP 443 should be allowed outbound for all intended interactions with AWS Analytics (S3, Rekognition, etc.).
1.7 AWS Services
The Cloud AI platform makes use of the following AWS services:
Rekognition (image labelling)
Comprehend (language detection in transcription)
Translate
Transcribe
You must verify that these services exist in the AWS region you're setting up in. Specifically Trans-late's Bulk functionality is not available in every region. Generally speaking information about availability of AWS functions can be found here:
https://docs.aws.amazon.com/general/latest/gr/aws-service-information.html
Just browse to the desired service and check the API availability in your target region. Below is a list of the services we use:
https://docs.aws.amazon.com/general/latest/gr/rekognition.html
https://docs.aws.amazon.com/general/latest/gr/comprehend.html
https://docs.aws.amazon.com/general/latest/gr/transcribe.html
https://docs.aws.amazon.com/general/latest/gr/translate-service.html
https://docs.aws.amazon.com/general/latest/gr/s3.html
https://docs.aws.amazon.com/general/latest/gr/ec2-service.html
For additional confirmation, see the below information to visually confirm availability:
Rekognition https://console.aws.amazon.com/rekognition/home?region=us-east-1#/
All necessary rekognition functions should be available in all regions, however you can verify by checking that Object and Scene Detection is available.
Comprehend https://console.aws .amazon. com/comprehend/v2/home?region=us-east-1#welcome
Check the left side for 'Analysis Jobs'. This is used for automatic language detection for translation. Be aware that Amazon charges relatively more for this function than other services. It can be manually disabled in the Cloud AI system on request.
Translation https://console.aws.amazon.com/translate/home?region=us-east-1#translation
Check the left side of the console, if 'Batch Translation' appears then it should be available in the selected region.
Transcription https://console.aws.amazon.com/transcribe/home?region=us-east-1#jobs
Check the left hand panel to ensure 'Transcription Jobs' is available.
Each of the above functions can be disabled depending on if the region you are operating in supports them.
1.8 IAM Items
Cloud AI makes use of a few different IAM Users/Roles:
Review Full Access User Used by Review to place data in the staging bucket. If you have already set up S3 for Review then this user will already be set up. Just make sure you add in the read/write permissions described in Section 3.2.
Cloud AI User Used by the cloud AI system to call specific AWS functions. The required permissions block is described in Section 3.3.
AWS Services Role This role will be provided to various AWS services to allow them to access the staging bucket. The required role is described in Section 3.4.
1.9 Data Security
1.9.1 AWS use of input data
One item to note is that AWS does by default use the data you provide to its analytics functions as a basis to improve their systems. For example, see this document on the Translate service:
https://aws.amazon.com/translate/faqs/
Under data privacy see the question, Are text inputs processed by Amazon Translate stored, and how are they used by AWS? As they mention in the article you message AWS to opt out of these sharing policies.
1.9.2 Data encryption
Both image labeling and transcription allow the use of KMS Keys for the encryption of input data. KMS is usually desirable as the data sent to AWS are encrypted by keys specific to your account/client.
Bulk translation however does not allow the use of KMS at time of writing. This is a limitation on AWS's side. To that end we encrypt data with AWS's generic server-side encryption when sending data to translation. This doesn't provide the same features as KMS, but does still ensure encryption at rest.
1.10 On Prem Installation Versus SaaS Considerations
Note that Cloud AI setup is required to enable some features of Review. Archiving, uploader, and sharable links rely upon S3 which is why these items are not supported in on-premises installations. These are lists of features either requiring extra configuration or unavailable in on-premises installations.
Requires Extra Configuration/AWS Account
Translation
Transcription
Image Labeling
Not Available
Easy archiving (case management screen)
Web Uploader
E-mailing link to a completed export (new feature to 10.3 not supported on prem)
2 Machine-Specific Setup Instructions
2.1 Orchestration
Orchestration will have the following features set up on it:
Mongo Database
Python-based flask API
Translation Worker
Image Labeling Worker
Transcription Finisher
Archiving/Transcription Work Monitor
Below we describe the steps necessary to set up this Orchestration server:
Unzip the RevealCloudAI.zip package at /opt/reveal/.
Run the bash script located here:
/opt/reveal/RevealCloudAI/ Installation / orchestration_install . sh This script will perform the following:
Install and Configure MongoDB
Install Python3
Install the AWS CLI
Install several Python3 Libraries
Install and Configure NGINX
Install and Configure a Python uWSGI Virtual Environment
Set up Reveal Config Files
Install several systemd services
Assuming the script ran correctly, you should have two config files here:
/etc/Cloud_API.config
/etc/cloud—ai—automation.config
Edit both of these config files and fix values as necessary.
To test, you can run the following in the order below, making sure to double-check the status of every service after starting:
systemctl start mongod
systemctl start nginx
systemctl start reveal_cloud_ai_api.service
systemctl start image_labeling_worker.service
systemctl start reveal_cloud_ai_monitor.service
systemctl start transcription_worker.service
systemctl start translation_worker.service
2.2 Transcription Master
Transcription Master will have the following features set up on it:
FFMPEG/FFPROBE Install
Transcription Master
Below we describe the steps necessary to set up this Transcription Master server:
Unzip the RevealCloudAI.zip package at /opt/reveal/.
Run the bash script located here:
/opt/reveal/RevealCloudAI/Installation/transcription_install.sh
This script will perform the following:
Install Python3
Install several Python3 Libraries
Download FFMPEG and FFPROBE
Set up Reveal Config Files
Install the Transcription Master systemd service
Assuming the script ran correctly, you should have a config file here:
/etc/Cloud_API.config
Edit this config file and fix values as necessary.
To test startup, you can run the following:
systemctl start transcription_master.service
3 AWS IAM Setup Items
In this section we describe the necessary items to set up within AWS.
3.1 KMS Policy
Replace the users here as necessary. The user 'revealdata-s3store-000000-fullaccess' represents the configured AWS Credentials for Review, while 'svc-cloud-api-us' represents the configured users for the CloudAl system.
This KMS key will be used by Review to encrypt data being sent to the CloudAl system. It will also be used by the CloudAl for submitting Image Labeling and Transcription jobs. Translation jobs will use generic AWS server-side encryption per AWS limitations.
{ "Version": "2012-10-17", "Id": "key-consolepolicy-3", "Statement": [ { "Sid": "Enable IAM User Permissions", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::326122048023:root" }, "Action": "kms:*", "Resource": "*" }, { "Sid": "Allow use of the key", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::326122048023:user/revealdata-s3store-000000-fullaccess", "arn:aws:iam::326122048023:user/svc-cloud-api-us" ] }, "Action": [ "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt*", "kms:GenerateDataKey*", "kms:DescribeKey", "kms:ListAliases" ], "Resource": "*" }, { "Sid": "Allow attachment of persistent resources", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::326122048023:user/revealdata-s3store-000000-fullaccess", "arn:aws:iam::326122048023:user/svc-cloud-api-us" ] }, "Action": [ "kms:CreateGrant", "kms:ListGrants", "kms:RevokeGrant" ], "Resource": "*", "Condition": { "Bool": { "kms:GrantIsForAWSResource": "true" } } } ] }
3.2 IAM User for Review (when using local storage)
Replace 'revealdata-analytics-temp-us' with your staging bucket name.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::revealdata-analytics-temp-us/*" ], "Effect": "Allow" }, { "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::revealdata-analytics-temp-us" ], "Effect": "Allow" } ] }
3.3 IAM User for CloudAl
Replace 'revealdata-analytics-temp-us' with staging bucket name same as the IAM User for Review in Section3.2. Replace 'arn:aws dam::326122048023:role/CloudAI-AccessAnalyticsTempUS' with the ARN of a role that will allow AWS services to access the analytics bucket. Role described in Section 3.4.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "transcribe:*", "translate:*", "rekognition:*", "comprehend:*" ], "Resource": "*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "iam:PassRole", "Resource": [ "arn:aws:iam::326122048023:role/CloudAI-AccessAnalyticsTempUS" ] }, { "Sid": "VisualEditor2", "Effect": "Allow", "Action": "s3:*", "Resource": [ "arn:aws:s3:::revealdata-analytics-temp-us/*", "arn:aws:s3:::revealdata-analytics-temp-us" ] } ] }
3.4 Role for AWS Services to access staging bucket
Replace 'revealdata-analytics-temp-us' with your staging bucket name.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::revealdata-analytics-temp-us/*" ], "Effect": "Allow" }, { "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::revealdata-analytics-temp-us" ], "Effect": "Allow" } ] }
Additionally, the role here must have the following Trust Relationship set:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "comprehend.amazonaws.com", "transcribe.amazonaws.com", "translate.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }
This trust relationship is set in the following location:
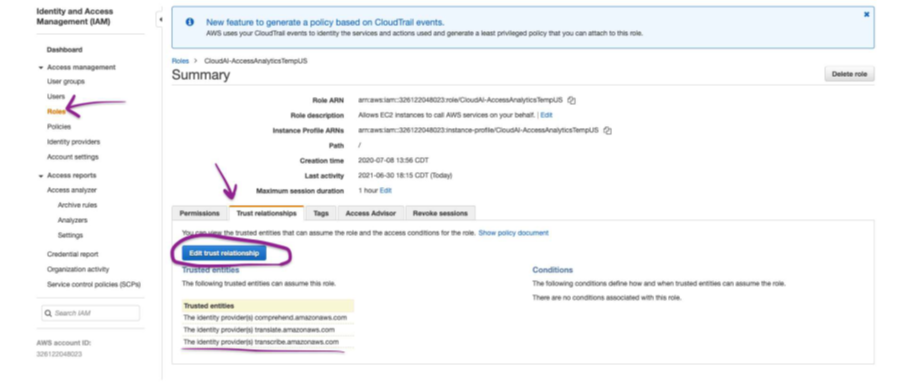
4 Testing
The most straightforward way to test
In the RevealCloudAI package there's a directory named 'testing' that contains a few scripts to facilitate testing the system:
RevealCloudAI/testing % is
__init__ .py testing_labeling.py testing_transcription .py testing_translation.py
Generally speaking each script can be run in the following manner:
python testing_transcription.py directory_with_audio —h 'http://1.2.3.4:5000/api/ '
Each should attempt to push documents to the CloudAl and wait for results to be returned.