Reviewers can train the COSMIC model by reviewing documents using different queues. COSMIC queues are designed to provide documents to reviewers for tagging.
Click the TRAINING tab on the main page to open COSMIC Queue Selector:
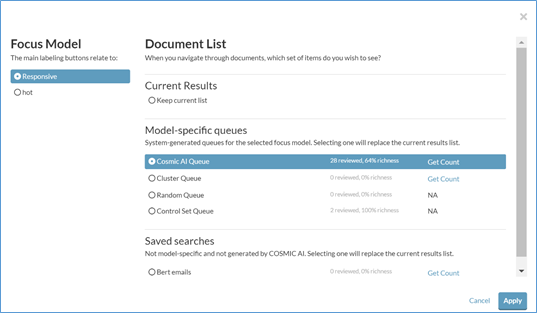
The options on the COSMIC Queue Selector page are:
Focus Model:
Under Focus Model select which COSMIC Group will be primary for purposes of tagging.
Document List:
Select which document set you would like to work with.
Current Results: this option will randomly select documents from the currently loaded documents set.
Model-specific queues:
COSMIC AI Queue: the training queue used to interactively work with the COSMIC service. When using this queue, the COSMIC service automatically classifies documents every time reviewers finish tagging a certain number of documents. Samples will be drawn based on current COSMIC scores and sent to reviewers for confirmation. This is the recommended way to review documents for the bulk of the COSMIC review.
Tip
The training queue will only be available after a reviewer provides a minimum number of “positive” documents plus one negative document. The minimum positive documents required is defined in the Minimum Positive Examples setting in the COSMIC Mission Control option.
Cluster Queue: this queue is only available when clustering is enabled; each cluster is guaranteed to have at least one sample document. This queue is typically used at the beginning of the COSMIC process when a reviewer needs to do a walkthrough of the dataset to enable the training queue.
Random Queue: the random queue is used to randomly pull documents from the population; this queue is typically used at the beginning of the COSMIC process when a reviewer needs to provide a minimum number of documents to enable the training queue.
Control Set Queue: this queue provides Control Set documents.
Saved Search Queue: this queue is based on a saved search that a user creates; the system will randomly draw document samples based on the saved search population.
Click Get Count to get number of documents available for that queue. Click Apply to enter the thread viewer to start reviewing documents.