Creating Document Text Sets
Text Sets are administered in the Reveal Review Manager under the Project Setup panel, using the Text Sets link. Text sets are searchable text groups defined by import stream, for example extracted text, optical character recognition (OCR), translation or transcription. Each may be indexed separately and have its parameters defined, including maximum document size and edited common words lists. The sets to be imported and indexed are selected during Document import.
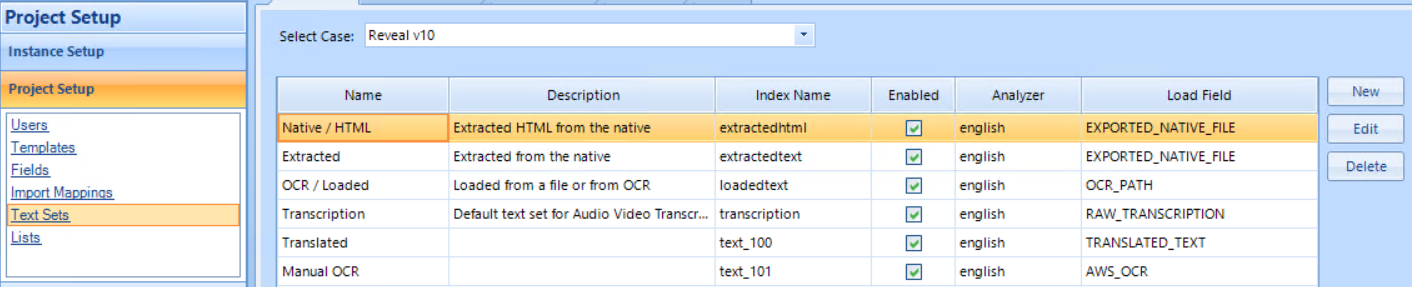
Default text sets in a newly-created Reveal Project are:
Native / HTML - Extracted HTML from native files.
Extracted - Extracted text from native files, such as Word documents, email messages, PowerPoint slides or Excel spreadsheets.
OCR / Loaded - Text loaded from a file or from OCR text documents accompanying images.
Transcription - Default text set for audio/video transcriptions.
Additional text sets may be added for Translations, for Manual OCR, or for sets of documents requiring a specially-defined Common Words list.
Note
As will be seen below, text sets require that you specify the path to the text files to be imported. This must be done before creating the text set, so the first thing to be done when creating a text set is to create the field that will hold the path to the text files if it does not already exist.
To create a field, go to Project Setup -> Fields and click New Field. The Field Table Name should be set out in caps with an underscore character separating any words; there is no such constraint on the Field Display Name. Field Data Type should remain as Text. Save with remaining default settings by clicking Add Field. See Creating New Fields for more information.
To create a text set:
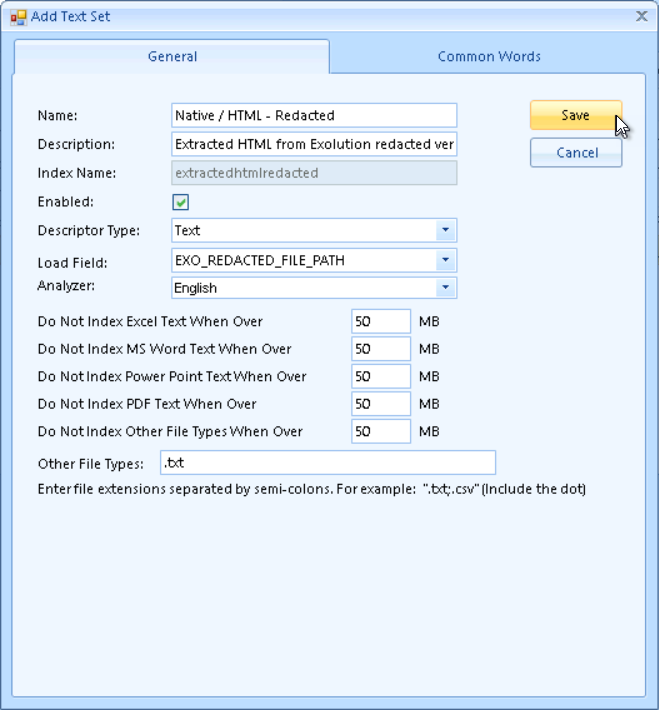
General Tab
Open Text Sets in the Project Setup pane within Reveal Review Manager.
Click the New button. You will then be presented with a number of items to configure for the new text set:
Name is how the text set will be referenced in Reveal in areas such as indexing, searching, and during review. The name should readily identify the origin or character of the documents to be included in the text set. E.g., Native / HTML - Redacted.
Description allows you to more fully describe the Text Set for ease of reference.
Enabled controls whether the Text Set will be available for use.
Descriptor Type identifies the kind of text in the set:
Text - Extracted or OCR text.
HTML - Native, coded text.
AV_Transcribe - audio/visual transcription.
Load Field is the field used to link text or native paths for indexing.
Analyzer is the text analyzer that is used on the extracted text prior to indexing. This should be set to the expected source language for your documents.
You can now control the various indexing size limits on a Text Set level, instead of across an entire case. In general, documents larger than the indicated file type defaults of 50MB are considered to contain too many words and vague or repeated terms to be useful, but this may be modified to fit the circumstances of the case and the nature of the documents to be imported to this Text Set.
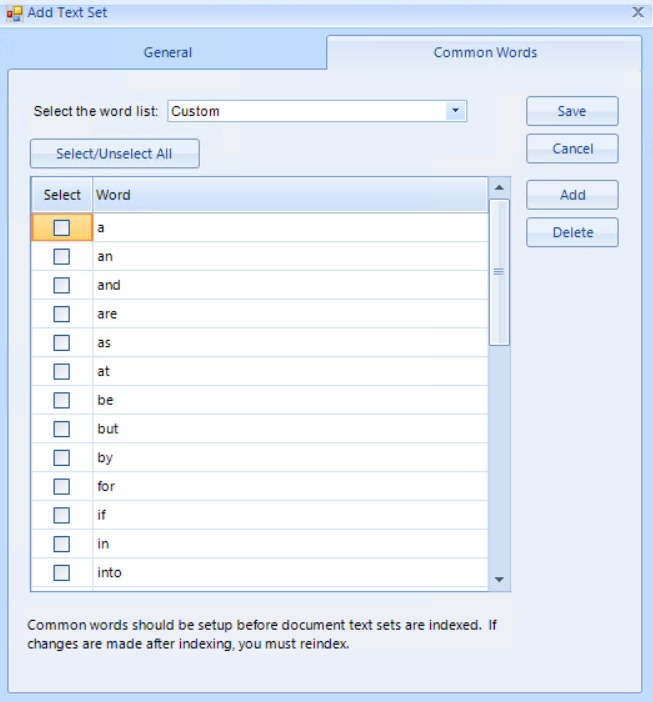
Common Words Tab
Common Words are those deemed too pervasive in the language for useful indexing and searching. The Common Words set for an index can be customized on the Text Set's Common Words tab.
Circumstances of the case may move a Project Manager to modify this list. For example, in a securities matter you may wish to remove the word "put" from the Common Words list so that this kind of action can be searched, if not for the entire case, then a set of document supplied by a key Custodian.
Caution
If you update the Common Words list you must delete its associated current indexes and then reindex to reflect the changes.